But, many are (finally) realizing that it’s not for everyone. Most of us aren’t at the scale of Netflix, LinkedIn, etc. and therefore don’t have the organizational manpower to offset the overhead of a full-blown microservices architecture.
An alternative to a full-blown microservices architecture that’s been getting a lot of press lately is called “modular monoliths.”
Shouldn’t well-written monoliths be modular anyways?
Sure. But modular monoliths are done in a very intentional way that usually follows a domain-driven approach.
Summary / Table Of Contents
This is part of the 2019 C# Advent! Take a look at all the other awesome articles for this year!
Here are the main sections in the article in case you would like to skip certain parts:
- Introduction / Why Modular Monoliths?
- Building A Modular Monolith With .NET Core Razor Class Libraries
- Building A Composite UI With Blazor/Razor Components
The GitHub repo for everything in this article is here.
Why Modular Monoliths?
The biggest benefits that microservices give us (loose coupling, code ownership, etc.) can be had in a well-designed modular monolith. By leveraging the domain-driven concept of bounded contexts, we can treat each context as an isolated application.
But, instead of hosting each context as an independent process (like with microservices), we can extract each bounded context as a module within a larger system or web of modules.
For example, each module might be a .NET project/assembly. These assemblies would be combined at run-time and hosted within one main process.
Each module would own everything from UI components, back-end business/domain logic to persistence.
Compared to microservices, the benefits of modular monoliths include:
- In-memory communication between contexts are more performant and reliable than doing it on the network
- A much simpler deployment process for smaller teams
- Retain boundaries and ownership around specific contexts
- Simplified upgrades to contexts/services
- Modules are “ready” to be extracted as services if needed
I see modular monoliths as a step within the potential evolution of a system’s architecture:

For domain-driven approaches, starting with a modular monolith might make the most sense and is definitely worth considering.
Here’s a more in-depth primer on modular monoliths by Kamil Grzybek if you’re interested.
How Can I Build Them?
There are many ways to build modular monoliths!
For example, Kamil Grzybek has created a production-ready modular monolith sample.
I personally prefer less separation within each bounded context / module, but his example is super detailed and worth looking at!
And, of course, Kamil says it well in his repo’s disclaimer:
The architecture and implementation presented in this repository is one of the many ways to solve some problems
In this article, we’ll be looking at a much simpler approach to building modular monoliths. Again, the direction and implementation depends on your needs (business requirements, team experience, time-to-market required, etc.)
We’ll be looking at one way that’s unique to .NET Core by using a new-ish feature of .NET Core called razor class libraries. Razor class libraries allow you to build entire UI pages, controllers and components inside of a sharable library! It’s the approach I’ve used for Coravel Pro and enables some exciting possibilities.
Life Insurance Application
I recently wrote an article about using some domain-driven approaches to think about and re-design an insurance selling platform I once worked on.
To keep things simple for now, let’s imagine we’ve determined two bounded contexts from this domain:
- Insurance Application
- Medical Questionnaire
The specific details are not so important since the remainder of this article will look at implementation and code.
The structure of our solution will roughly look like the following - with a .NET Core web application as the host:
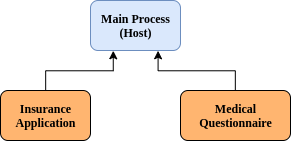
Creating Our Skeleton
Let’s implement the skeleton for our modular monolith and use razor class libraries as a way to implement our bounded contexts.
First, create a new root host process:
dotnet new webapp -o HostApp
Next, we’ll create our two modules as razor class libraries:
dotnet new razorclasslib -o Modules/InsuranceApplication
dotnet new razorclasslib -o Modules/MedicalQuestions

Then, we’ll reference our modules from the host project.
From within the host project:
dotnet add reference ../Modules/InsuranceApplication/InsuranceApplication.csproj
dotnet add reference ../Modules/MedicalQuestions/MedicalQuestions.csproj
Building Our First Module
Navigate to the Insurance Application module at Modules/InsuranceApplication.
Your razor class library will have some sample Blazor files, www folder, etc. You can remove all those generated files.
Let’s build a couple of Razor Pages that will be used as this bounded context’s UI:
dotnet new page -o Areas/InsuranceApplication/Pages -n ContactInfo
dotnet new page -o Areas/InsuranceApplication/Pages -n InsuranceSelection
You might have to go into your razor pages and adjust the generated namespaces. In my example, I changed them to
InsuranceApplication.Areas.InsuranceApplication.Pages.
Oops! It Doesn’t Work!
Navigate back to the HostApp web project and try to build it.
It will fail!
Our razor class libraries are trying to use razor pages - which is a web function. This requires referencing the appropriate reference assemblies.
Before .NET Core 3.0, we would have added a reference to some extra NuGet packages like Microsoft.AspNetCore.Mvc, etc. As of .NET Core 3.0, many of these ASP related packages are actually included in the .NET Core SDK.
For some projects, this breaking change can cause issues and confusion! For more details, check out Andrew Lock’s in-depth look at this issue.
So, let’s change the project files of our two razor class libraries to the following:
<Project Sdk="Microsoft.NET.Sdk.Razor"> <PropertyGroup> <TargetFramework>netcoreapp3.0</TargetFramework> <AddRazorSupportForMvc>True</AddRazorSupportForMvc> </PropertyGroup> <ItemGroup> <FrameworkReference Include="Microsoft.AspNetCore.App" /> </ItemGroup></Project>Yes, I removed all the boilerplate Blazor code since the appropriate references are included in the
FrameworkReference.
It’s Alive!
Go into the razor pages you created and add some dummy HTML.
For example:
@page@model InsuranceApplication.Areas.InsuranceApplication.Pages.ContactInfoModel@{}<h1>Insurance Contact Info</h1>Try running your host application and navigate to /InsuranceApplication/ContactInfo and /InsuranceApplication/InsuranceSelection.
Both pages should display. Cool!
UI Flow: Beginning The Insurance Application
Let’s look at building out a basic flow between our two modules.
First, in the HostApp project, in your Pages/Index.cshtml file add the following HTML:
<a href="/InsuranceApplication/ContactInfo">Begin Your Application!</a>That will give us a link to click from our home screen to begin the flow through our application logic.
UI Flow: Inside The Insurance Application Module
In your ContactInfo.cshtml file within the InsuranceApplication project, insert the following:
@page@model InsuranceApplication.Areas.InsuranceApplication.Pages.ContactInfoModel@addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers<h1>Insurance Contact Info</h1><form method="post"> <label>Email:</label> <input asp-for="EmailAddress" required type="email" /> <button type="submit">submit</button></form>In ContactInfo.cshtml.cs, add the following:
using System;using System.Collections.Generic;using System.Linq;using System.Threading.Tasks;using Microsoft.AspNetCore.Mvc;using Microsoft.AspNetCore.Mvc.RazorPages;namespace InsuranceApplication.Areas.InsuranceApplication.Pages{ public class ContactInfoModel : PageModel { [BindProperty] public string EmailAddress { get; set; } public IActionResult OnPostAsync() { Console.WriteLine($"Email Address is {this.EmailAddress}."); return RedirectToPage("./InsuranceSelection"); } }}This will allow us to enter an email address and move to the next page in our flow.
In the InsuranceSelection.cshtml page - just add a link to keep things simple:
<a href="/MedicalQuestionnaire/Questions">Next<a>You can imagine that this page would allow the user to select a specific insurance plan they want to apply for.
UI Flow: Medical Questionnaire Module
You might have noticed that we never created any razor pages in the Medical Questionnaire module. Let’s do that now.
Navigate to the root of the MedicalQuestions project and enter the following from your terminal:
dotnet new page -o Areas/MedicalQuestionnaire/Pages -n Questions
Again, you might need to adjust the generated namespaces.
Within the Questions.cshtml file, add a link:
<h1>Medical Questionnaire</h1><a href="/">Finish<a>Try running your host project with dotnet run and run through the entire UI!
Composite UIs With Blazor Components
When working with these kinds of loosely coupled modules a question arises:
What happens when we need to display information from multiple bounded contexts on the same screen?
Usually, we resort to building composite UIs.
These are UIs where various parts of the UI are rendered and controlled by components owned by a specific bounded context, service or module.
As you can see in the image above, each component might be owned by a different back-end module and would be isolated from and loosely coupled to the other modules.
Let’s build a simple composite UI using some exciting new .NET Core 3.0 technologies!
Configure Blazor Components
We need to configure our host application to support the new blazor/razor components.
- Add the following script to
Pages/Shared/_Layout.cshtml:
<script src="_framework/blazor.server.js"></script>- In
Startup.csinConfigureServicesadd:
services.AddServerSideBlazor();- In the
Configuremethod:
app.UseEndpoints(endpoints =>{ endpoints.MapRazorPages(); endpoints.MapBlazorHub(); // Add this one.});Create Insurance Application Component
Navigate to the InsuranceApplication project’s root directory and execute the following:
dotnet new razorcomponent -o ./Components -n ApplicationDashboard
Replace the contents of your new razor component with the following:
@using Microsoft.AspNetCore.Components.Web<h3>Application Dashboard</h3><p> Time: @currentTime</p><button @onclick="Update">Update</button>@code { private string currentTime = DateTime.Now.ToString(); private void Update() { currentTime = DateTime.Now.ToString(); }}Create Medical Questions Component
Do the same steps within the MedicalQuestions module to create a dummy razor component (but change the title of the component).
Putting It Together
Now, back in your host application project, within the Pages/Index.cshtml page, add the following to the top of the file:
@page@using InsuranceApplication.Components // Add this.@using MedicalQuestions.Components // Add this.@model IndexModelThen, in the middle of your HTML page, add:
<div class="row"> <div class="col-6"> @(await Html.RenderComponentAsync<ApplicationDashboard>(RenderMode.ServerPrerendered)) </div> <div class="col-6"> @(await Html.RenderComponentAsync<QuestionsDashboard>(RenderMode.ServerPrerendered)) </div></div>Finally… start your host project using dotnet run!
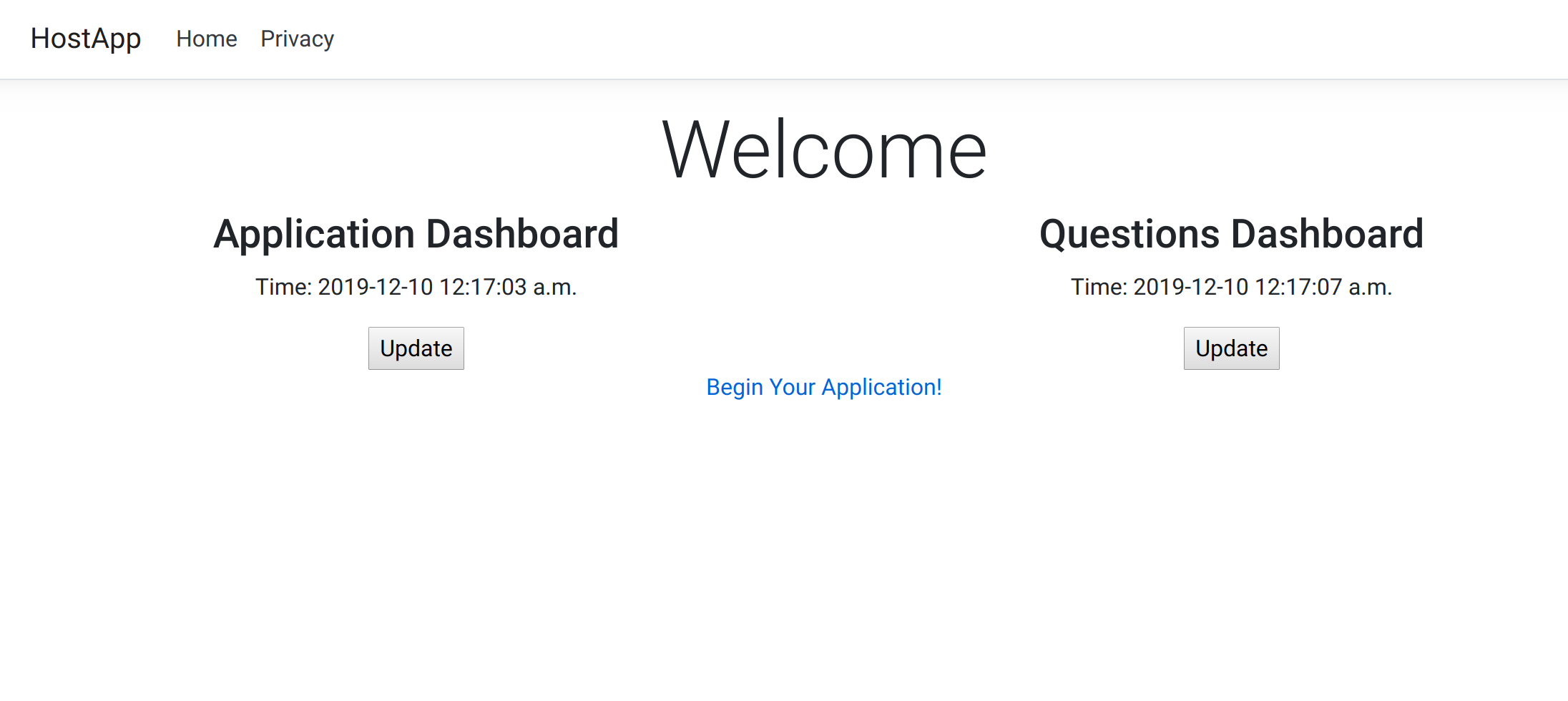
Any time one of the components needs to be changed, the host application will (most likely) not need to change. Both bounded contexts are still isolated from each other but our architecture allows us to be smart about how we display that information.
Note: There are other ways to build these types of components: view components, tag helpers, tag helper components, javascript components, etc.
Other Considerations
Modules can be deployed as NuGet packages so that they ultimately can be managed by independent teams and be isolated as true modules.
Each bounded context can:
- Use its own isolated database
- Have its own self-contained business logic
- Communicate with other bounded contexts by using messaging and domain events
- etc.
In terms of service/module interaction, any calls between modules could use a shared abstractions library which would be configured in DI at run-time to use the concrete service from the appropriate bounded context:
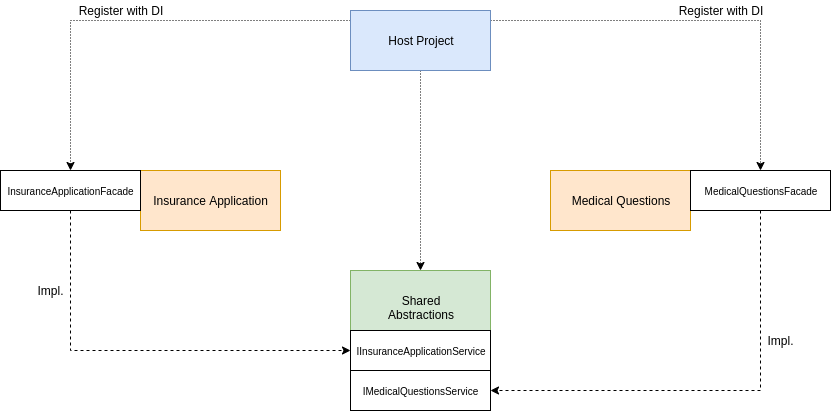
It doesn’t show on the diagram, but the Medical Questions context might need to get some information from the Insurance Application context in some scenarios where using messaging isn’t appropriate.
In this case, the Medical Questions code would use the IInsuranceApplicationService interface (from DI) to make those calls.
Then, at run-time, the host process would configure the concrete implementation (InsuranceApplicationFacade) to be given to anyone who asks for the interface.
This technique keeps each module loosely coupled and enforces a strict contract in terms of what one bounded context can be explicitly be “asked for”.
However, some might say the need to make direct calls to another bounded context is a sign that the boundaries are incorrect…a topic for another day.
Conclusion
I hope you found this article helpful and informative. I’m sure you can see that razor class libraries are a really exciting feature of .NET Core that hasn’t been talked about too much.
This is one way to use them and for some cases it might work really well!
Here are some resources about the topics we covered:
- Blazor
- Razor Components
- View Components
- Modular Monoliths Talk By Simon Brown
- Composite UIs for Microservices - A Primer By Jimmy Bogard
- Microsoft: Creating composite UI based on microservices
My Book
Check out my book about keeping your code healthy!

New Site!
I’ll be writing new content over at my new site/blog. Check it out!
Keep In Touch
Don’t forget to connect with me on:
]]>